The Need
The project that I developed in a large Chilean credit union between 2021 and 2022 arose from a reality that usually happens in many companies: the digital age brought the rush to implement many digital customer service channels. Long before that, the company already had a service bus for its internal applications, and the most convenient solution was to reuse it. However, it was not designed to support the magnitude of scale that those channels and applications brought.
What happened then was that several cycles of optimization and resizing of the integration layer took place, until the maintenance costs made it unfeasible to continue that way. The integration layer was no longer able to support the demand during the peak loads, collapsing and bringing down the entire network of dependants from that layer, whether internal or in the cloud. In the other hand, it wasn't feasible to migrate that core banking application to the cloud. The system had been implemented with legacy mainframe technology, so the magnitude and risks involved in that type of project made that alternative unattractive.
Then came the idea of decoupling the digital channels and applications in the cloud from the company's core systems: they would occupy native data sources in the cloud, alleviating the load generated on the integration layer. And data should be copied from legacy systems to those new data sources using the same ETL techniques that the technology teams were used to developing, with the same existing batch processing cycles.
Everything right from a technical perspective, right? Not exactly: the customers of those digital channels require quick information on their mobile phones, and they don't admit to wait until the next day to see a transaction completed right now. When you think about how to solve this problem is when the data streaming integrated with real-time transaction capture starts to make sense!
A Creative and Robust Solution
In simple terms, real-time transaction data capture is the logging, in the least possible invasive way, of every insert, update or delete that occurs in a source database. With that, it is possible to replicate the information in another destination database thorough executing the same sequence of operations originally registered. There are many ways to do that. An cost-efective alternative are using tools that capture native transaction logs from relational databases. They translate that information into a more open format, a json for example, and send the CDCs to the desired destination, in our case a data streaming cluster.
And what the reasoning about data streaming? The currently available tools bring an interesting combination of scalability, cost and flexibility that enables us to meet all the requirements of this type of project. With this kind of technology, it is possible to meet the highly unpredictable and variable load demand generated from the transactions in the company's core system and, at the same time, execute ETL operations in near real time. Also, if the system is well designed, the streaming platform can be used for all kinds of data analysis, such as fraud detection systems, machine learning or artificial intelligence. In the case of our project, the chosen streaming platform was Apache Kafka.
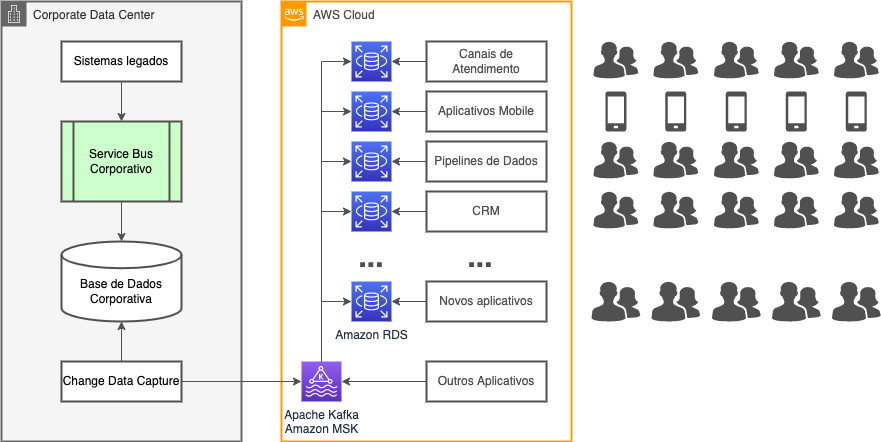
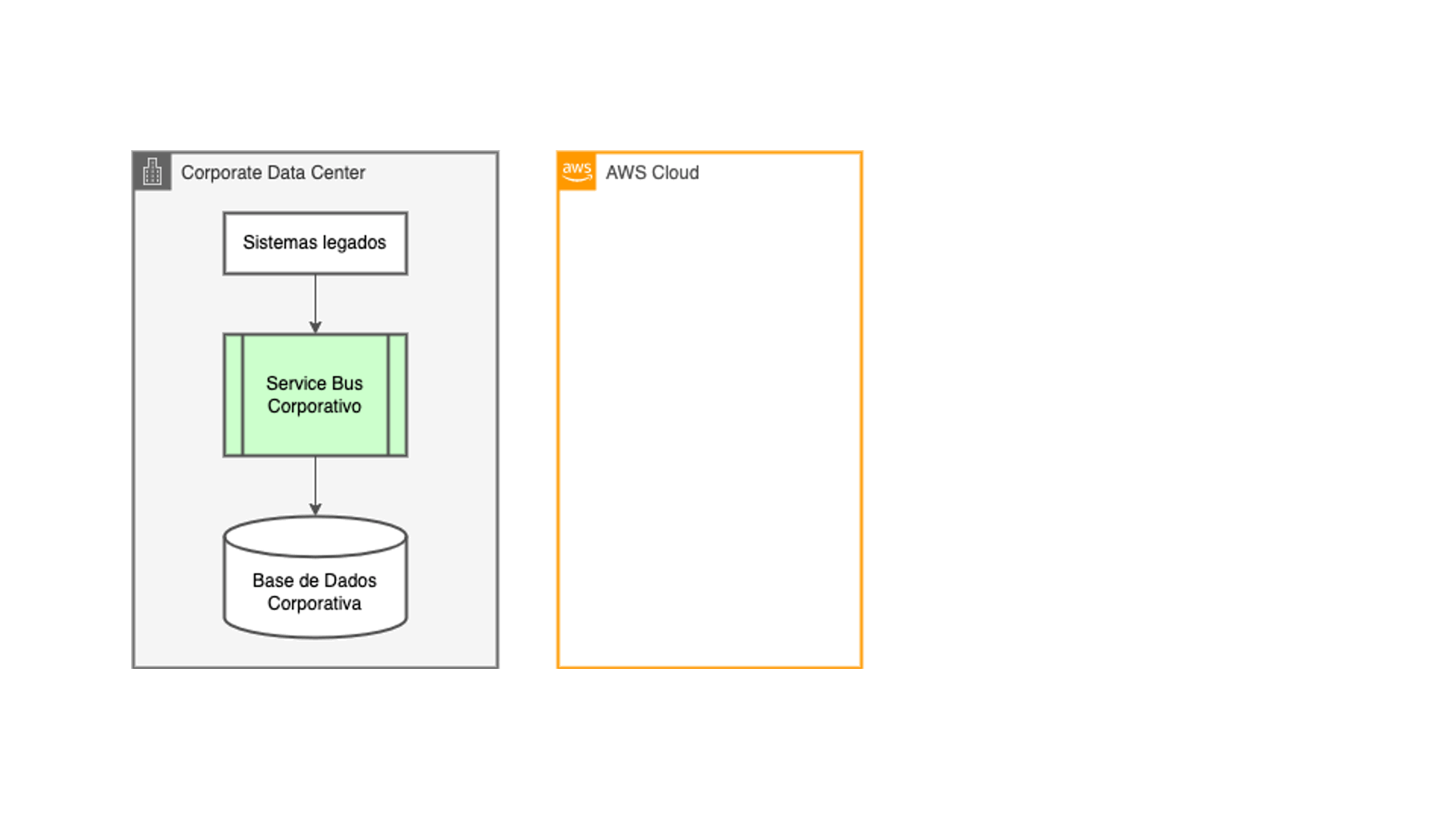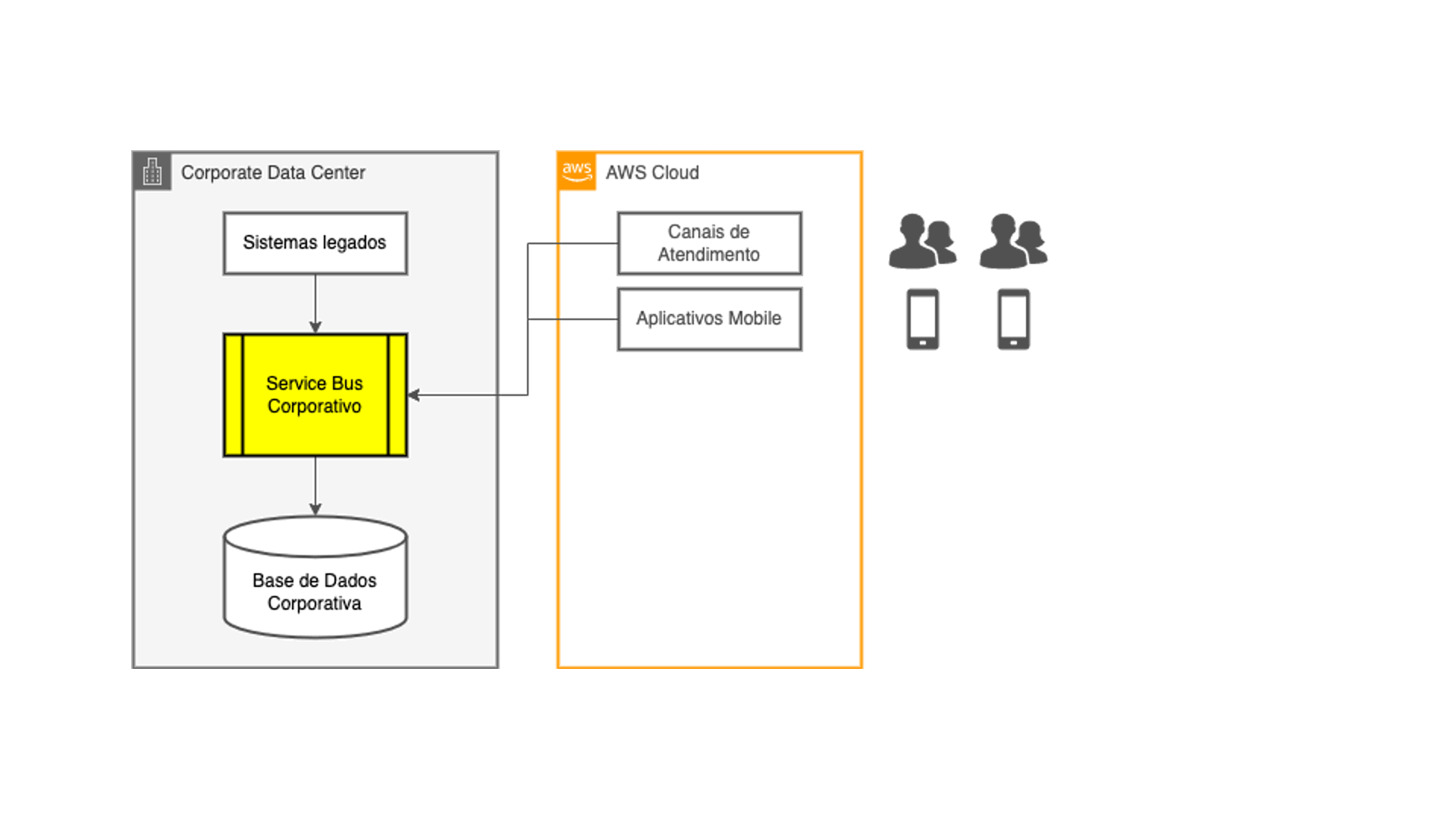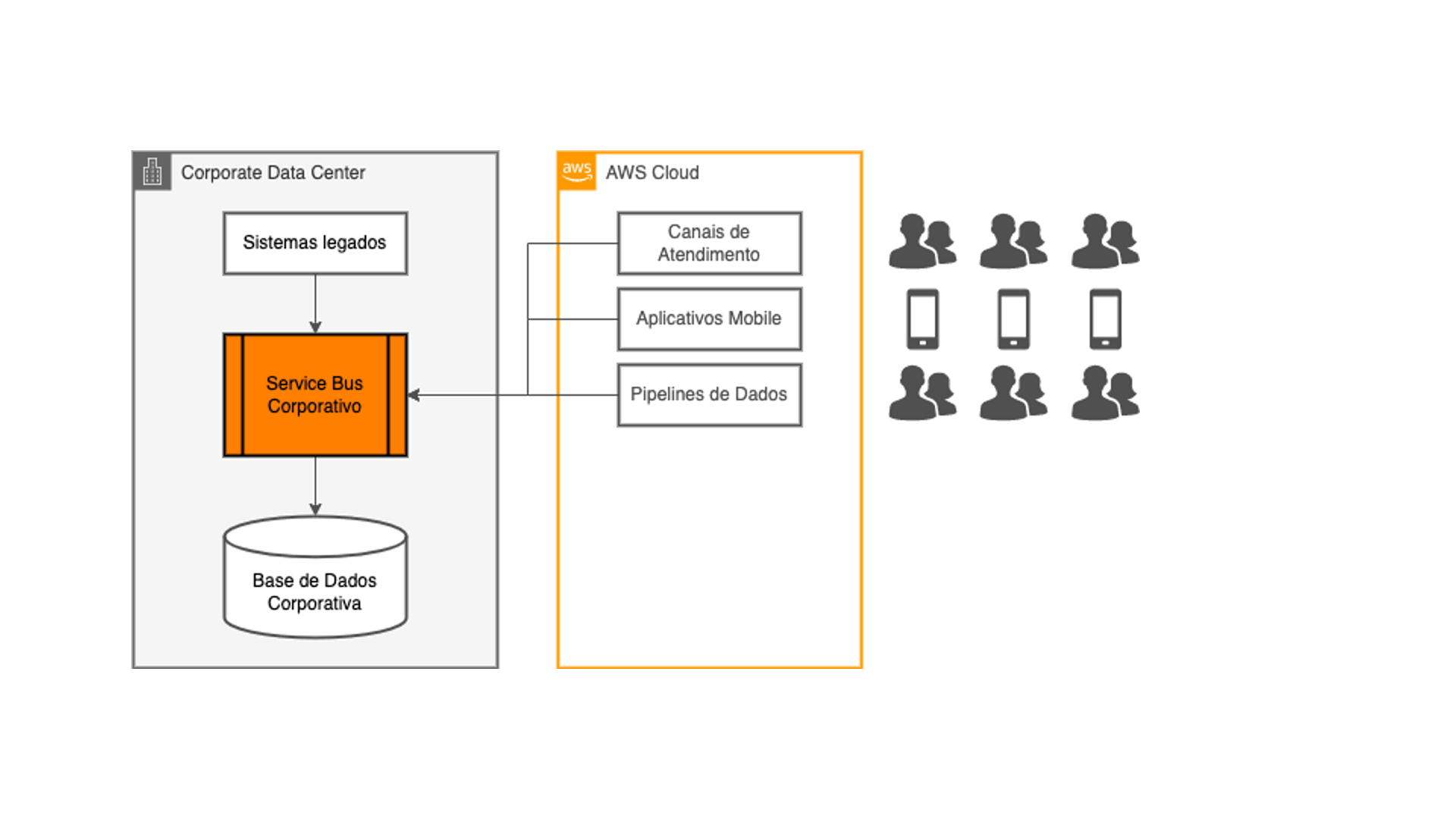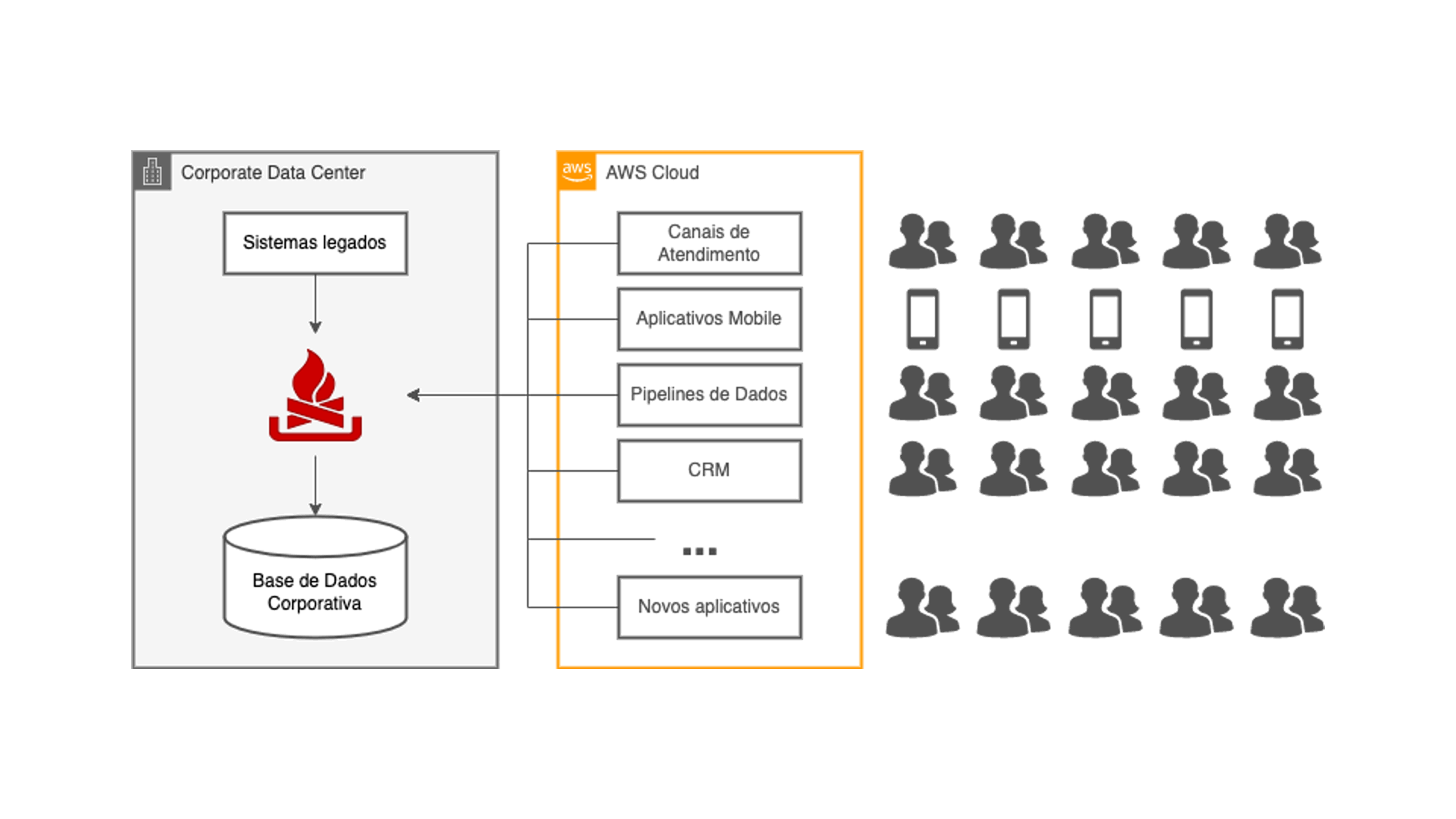
The diagram shows the main components of the data replication solution adopted in the project. We see that access to core system data no longer occurs through the service bus. Instead, a tool connects directly to the database, extracting the CDCs and sending them to the AWS MSK service managed by AWS, which is simply an Apache Kafka cluster.
Within the Kafka platform, all the necessary ETL transformations take place to make the source and destination data models compatible using Kafka Streams technology. The information is then sent by Kafka Connect connectors to the RDS databases created specifically for each cloud application. All of that ocurring in a near real time way compared to the original transaction.
The Challenges
And this new architecture solves everything? Obviously not! There are several challenges that appear both in the development and in the operation of this new type of system. Some of them we want to highlight here:
- Relational versus event-driven paradigm: The first challenge that arrises was with the development team. A system based on data streaming is essentially an event-driven system. Despite there being a natural equivalence between a data streams and relational tables, understanding the differences and similarities between both requires a shift in the way of thinking;
- Keeping track of compatibility and consistency of data models from both sides: in the legacy world, data is commonly not normalized. And even if they are normalized, data integrity shall not be take for granted, such as referential integrity for example. In addition, modern applications often use non-relational concepts, which can bring an additional challenge when developing data transformation operations;
- Legacy data model knowledge not complete or dispersed in the teams: Too often the people in the team's company that knows about legacy systems data models are very few, or that knowledge is dispersed among various team members, or even it's no longer within the company. As the systems were designed long ago, with programming paradigms no longer used, the knowledge and time required to extract information from these kind of systems shall not be underestimated;
- Exception handling and unpredicted cases: defining how to resolve unpredicted cases is as important as defining the mapping between the source and destination data. Neglecting aspects related to exception handling can cause huge problems when deploying this type of system in production. Using representative databases while developing is also essential to detect border conditions and lack of consistency in the data;
- Monitoring and Failure responses: once the data pipelines starts running, monitoring and failure response shall be constant, since now everything happens in real time and the response to those kind of events must be done quickly and swiftly. For that reason, all the aspects that allow automation must be considered, always thinking of reducing the response time when unpredicted things happens. All aspects, from automating the deployment of new versions to what should happen when inconsistent data arrives, through auto-scaling and auto-recovery from hardware and software failures, must be thought through and automated. That requires a new mindset and posture from development, architecture, and operations teams.
Those are just some of the challenges we had to overcome throughout the development of the solution. However, the benefits gained with the project are well worthed compared to the effort required to overcome them.
The Benefits
As a result, the load generated by those applications are now fully managed in the cloud, without overloading on-premise legacy systems. We list some of the benefits gained from the implementation of the solution:
- Real Time Data Availability: data is available for cloud applications practically at the same time as it was processed by core banking systems, providing customers with more agility in digital channels;
- Cheaper and More Resilient Legacy Systems: decoupling the cloud applications from the integration layers improved the stability of that layer, since the stress generated by the variable load from the cloud is treated with automatic scaling whitin the same cloud, where it is easier to adapt to variable demand and at the same time control the costs;
- New Possibilities for Exploring Business Data: the streaming platform brought new possibilities for data exploration in real time, from predictive analysis techniques to machine learning and artificial intelligence;
- More Agility Developing New Cloud Solutions: since it no longer depends on the legacy systems integration layer services, development teams can now focus only on their applications, improving the development times of their solutions.
Explore Posibilities
If this project catches your attention, I shall tell you that it is important to have support from an experienced company in the development and operation of this kind of replication system, and TruStep can support you on that path.
Contact us. Take the chat at the bottom right of our site. We are eager to understand your scenario in a conversation, show you more details about how we implement and operate this real time data replication solution through data streaming, and evaluate together how such a solution could help your business improve the attention to your customers.