La necesidad
El proyecto que desarrollé en una gran cooperativa de crédito chilena entre el 2021 y el 2022 surgió de una realidad que suele pasar en muchas empresas: la era digital trajo la premura para implementar muchos canales digitales de atención a los clientes. Mucho antes de eso, la empresa ya tenía un bus de servicios para sus aplicaciones internas, y la solución más conveniente fue reaprovecharlo. Sin embargo, el no fue diseñado para soportar la magnitud de escala que esos canales y aplicaciones aportaron.
Lo que sucedió fueron varios ciclos de optimización y redimensionamiento de esa capa de integración, hasta que el costo para mantenerla hizo inviable seguir por ese camino. En los momentos extremos de carga la capa de integración ya no daba abasto para soportar la demanda, colapsando y llevando con ella la disponibilidad de todas las aplicaciones dependientes de ella, fueran internas o en la nube. Tampoco migrar esa aplicación de core bancario para la nube no era factible. El sistema había sido implementado con tecnología mainframe legada, de modo que la magnitud y los riesgos involucrados en ese tipo de proyecto hacía con que esa alternativa fuera poco atractiva.
Surgió entonces la idea de desacoplar los canales digitales y aplicaciones en la nube de los sistemas core de la compañía: ellas ocuparían fuentes de datos nativas en la nube, aliviando la carga generada sobre la capa de integración. Y los datos deberían ser copiados desde los sistemas legados hacia esas nuevas fuentes de datos ocupando las mismas técnicas ETL que los equipos de tecnología estaban acostumbrados a desarrollar, con los mismos ciclos de procesamiento batch existentes.
Todo ajustado del punto de vista técnico, ¿verdad? No exactamente: los clientes de esos canales digitales requieren informaciones rápidas en sus teléfonos móviles, y no quieren esperar hasta el día subsiguiente para ver ahí una transacción finalizada ahora. ¡Justo al pensar acerca de esa cuestión que la idea de ocupar streaming de datos integrado con la captura de transacciones en tiempo real empieza a sonar!
Una Solución Creativa y Robusta
La captura de transacciones en tiempo real es el registro, de la forma menos invasiva posible, cada insert/update/delete que ocurre en la base de datos de origen. Con eso es factible replicar las informaciones en otra base de datos de destino ejecutando la misma secuencia de operaciones registrada en principio. Existen muchas maneras de hacer eso. Una alternativa con costo/beneficio adecuado son las herramientas de capturan los logs de transacción nativos de las bases de datos relacionales. Ellas traducen esa información en un formato más abierto, un json por ejemplo, y envía los CDCs para el destino deseado, en nuestro caso un cluster de streaming de datos.
¿Y por qué streaming de datos? Las herramientas disponibles actualmente traen una combinación interesante entre escalabilidad, costo y flexibilidad que nos que nos posibilita cumplir con todos los requerimientos de un proyecto de esa naturaleza. Con ella es posible atender la demanda muy poco predecible y variable de carga generada desde las transacciones en el sistema core de la compañía y, al mismo tiempo, ejecutar operaciones de ETL en tiempo cercano al real. Además, si el sistema es bien diseñado, la plataforma de streaming puede ser ocupada para todo tipo de análisis de datos, como sistemas de detección de fraudes o aprendizaje de máquina e inteligencia artificial. En el caso de nuestro proyecto, la plataforma de streaming elegida fue Apache Kafka.
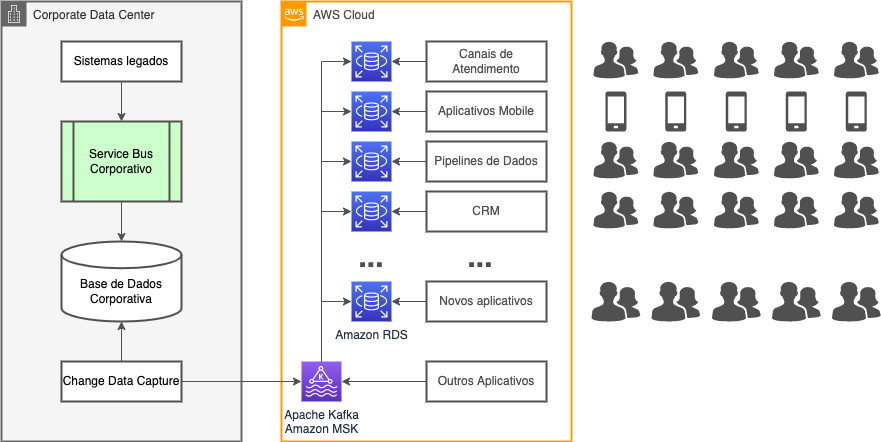
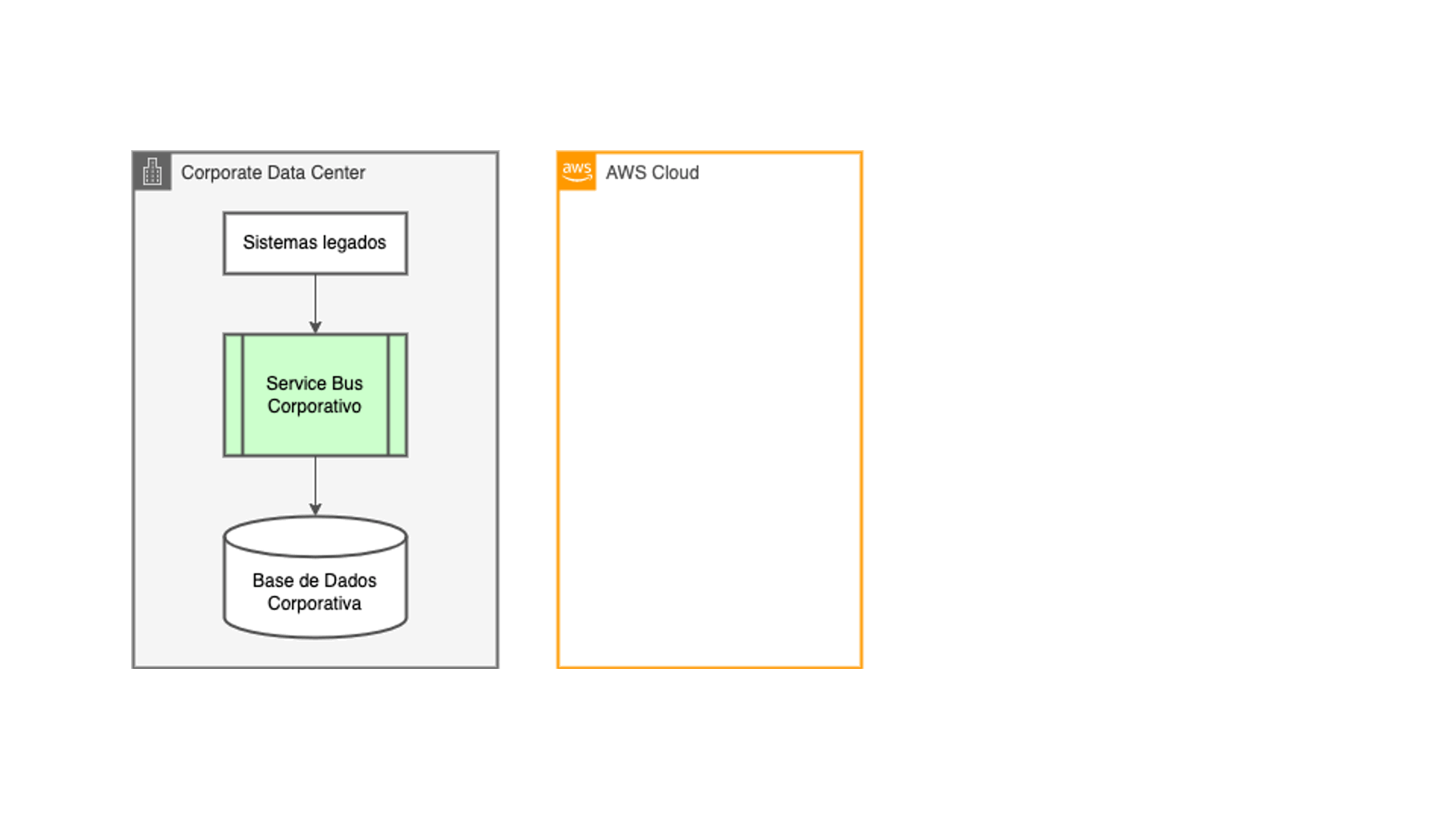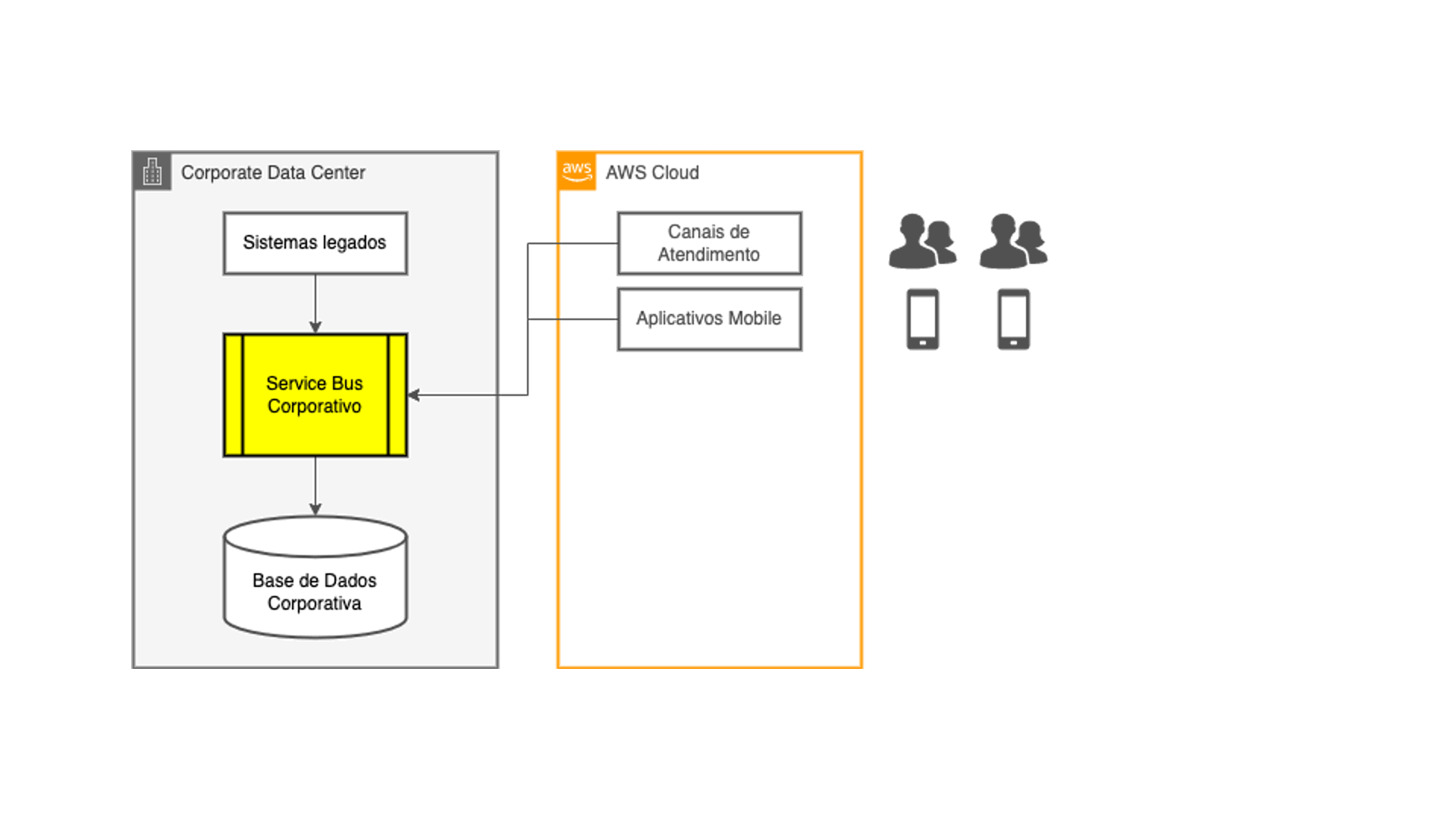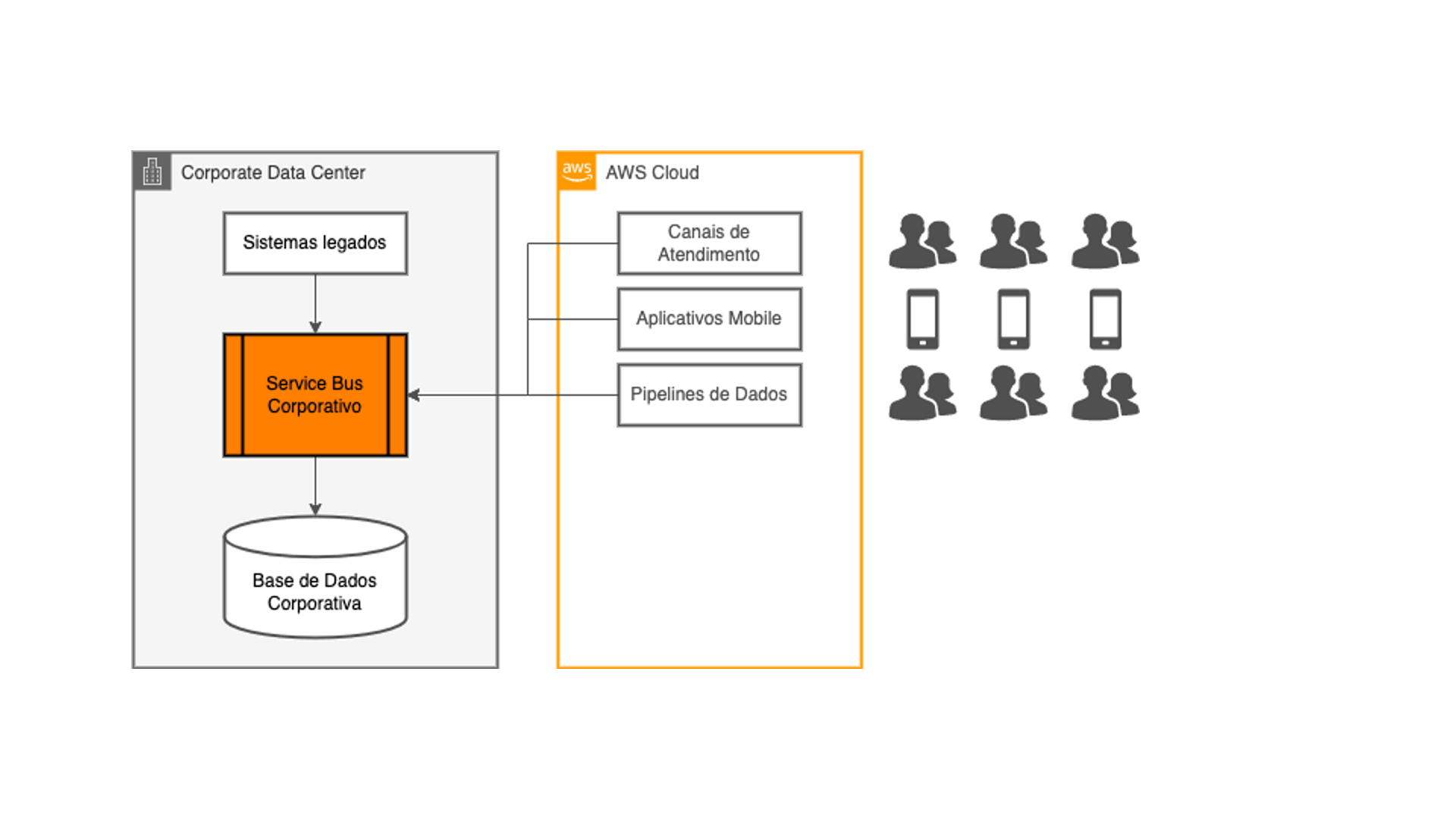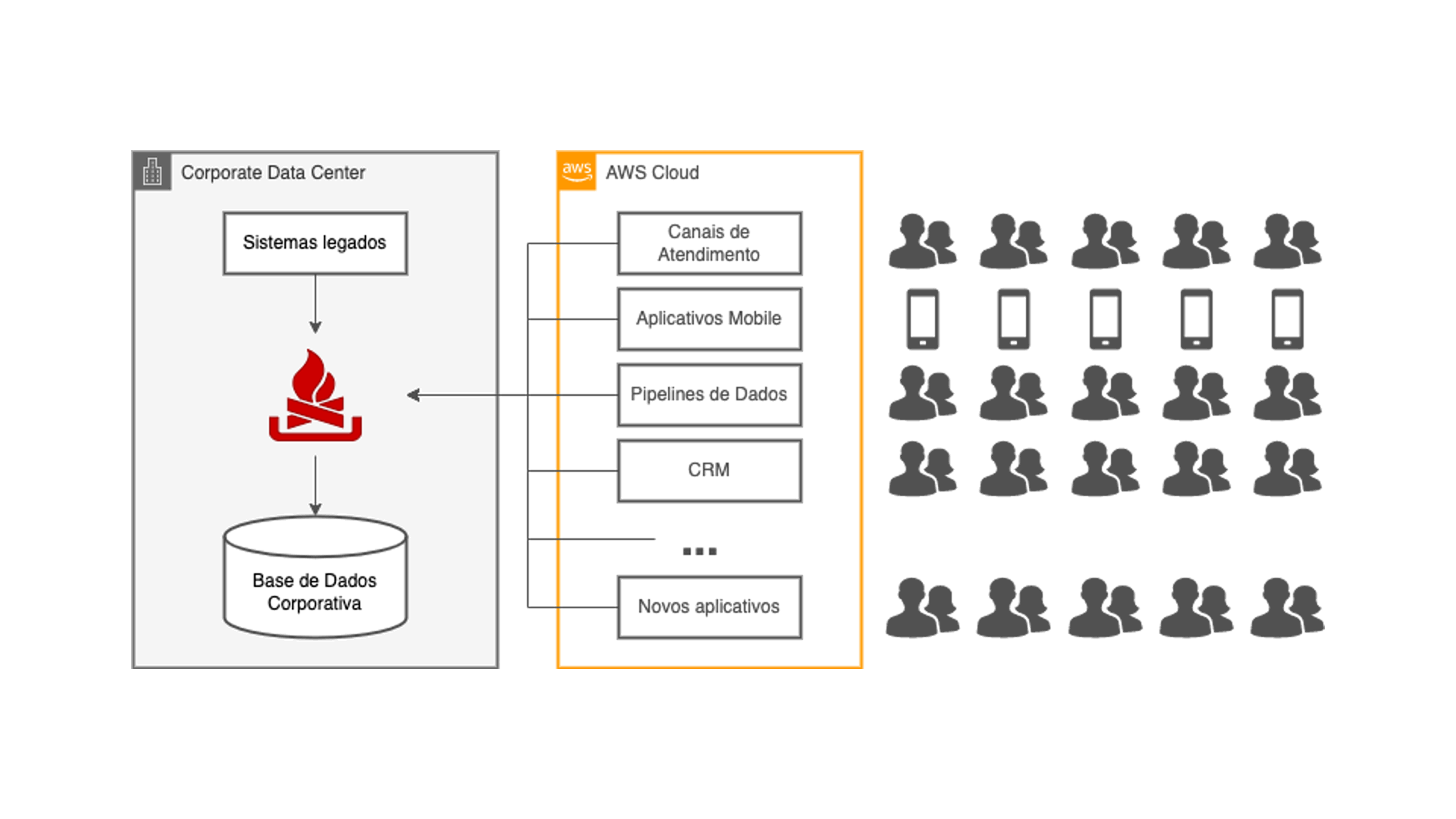
El diagrama muestra los principales componentes de la solución de replicación de datos adoptada en el proyecto. Vemos que el acceso a los datos del sistema core ya no ocurre a través del bus de servicios. En reemplazo, una herramienta se conecta directamente a la base de datos, extrayendo los CDCs y enviándolos hacia el servicio AWS MSK gestionado por AWS, que de manera sencilla es un cluster Apache Kafka.
Adentro de la plataforma Kafka ocurren todas las transformaciones ETL necesarias para hacer compatible los modelos de datos de origen y destino ocupando tecnología Kafka Streams. Entonces las informaciones son enviadas por conectores Kafka Connect para las bases de datos RDS creadas específicamente para cada una de las aplicaciones en la nube. Todo eso en una escala de tiempo muy cercana al tiempo real de la transacción original.
Los Desafíos
¿Y todo está resuelto con esa nueva arquitectura? Obviamente no. Existen varios desafíos que aparecen tanto en el desarrollo cuanto en la operación de ese nuevo tipo de sistema. Algunos de ellos queremos destacar:
- Paradigma relacional versus orientación por eventos: el primer desafío que surgió fue con el equipo de desarrollo. Un sistema basado en streaming de datos es en su esencia un sistema orientado por eventos. A pesar de existir una equivalencia natural entre un stream de datos y tablas relacionales, comprender as diferencias y similitudes entre ambos exigió un cambio de paradigma;
- Compatibilización y consistencia de modelos de datos: en el mundo legado muchas veces los datos no se encuentran en forma normal. Y aun que estuvieran normalizados, la integridad de los datos puede no ser garantizada por la base de datos, como por ejemplo la integridad referencial. Además, las aplicaciones modernas suelen ocupar conceptos no relacionales, lo que puede traer un reto adicionalal momento de desarrollar las operaciones de transformación de datos;
- Conocimiento del modelo legado no completo o disperso: muchas veces los sistemas legados poseen un modelaje de datos que pocas personas conocen, que se encuentra disperso entre varios miembros del equipo o incluso ya no se encuentra adentro de la compañía. Como son sistemas diseñados desde hace mucho, con paradigmas de programación ya no ocupados, el conocimiento y el tiempo necesarios para extraer las informaciones de esos tipos de sistemas no pueden ser subestimados;
- Tratamiento de excepciones y casos no previstos: definir cómo resolver los casos no previstos es tan importante cuanto definir el mapeo entre los dados de origen y destino. Descuidar aspectos relacionados al tratamiento de excepciones puede generar un gran problema en el momento de desplegar ese tipo de sistema en producción. Desarrollar ocupando bases de datos representativas también es fundamentalpara detectar condiciones de borde y falta de consistencia en los datos;
- Monitoreo y respuesta a fallas: una vez que los pipelines de datos empiezan a operar, el monitoreo y respuesta a fallas debe ser constante, pues ahora todo ocurre en tiempo real y la respuesta a esos eventos debe ser expedita. Por eso, todos los aspectos que permiten automatización deben ser considerados, siempre pensando en disminuir el tiempo de respuesta cuando pasan cosas no previstas. Todos los aspectos, desde la automatización del despliegue de nuevas versiones hasta lo que debe ocurrir cuando un dato no consistente llega, pasando por el auto escalamiento y auto recuperación de fallas de hardware y software, deben ser pensados y automatizados. Eso exige una nueva mentalidad y postura de los equipos de desarrollo, arquitectura y operaciones.
Esos son solo algunos de los retos que tuvimos que superar a lo largo del desarrollo de la solución. Sin embargo, los beneficios ofrecidos compensaron el trabajo necesario para superarlos.
Los Beneficios
Como resultado, la carga generada por esas aplicaciones ahora es totalmente manejada en la nube, y no sobrecarga los aplicativos legados on-premise. A continuación tenemos algunos de los beneficios verificados con la implementación de la solución:
- Disponibilidad de los Datos en Tiempo Real: los dados están disponibles para las aplicaciones en la nube prácticamente al mismo tiempo en que fueron procesados por los sistemas de core bancario, entregando a los clientes más agilidad en los canales digitales;
- Sistemas Legados más Estables y Económicos: desacoplar los aplicativos en la nube de las capas de integración mejoró la estabilidad de esa capa pues la presión generada por la carga variable desde la nube es tratada con escalamiento automático en la misma nube, donde es más fácil adecuarse a la demanda y al mismo tiempo controlar los costos;
- Nuevas Posibilidades para Explotar los Datos del Negocio: la plataforma de streaming trajo nuevas posibilidades de explotación de los datos en tiempo real a través de técnicas de análisis predictiva, aprendizaje de maquina e inteligencia artificial;
- Más Agilidad en el Desarrollo de Nuevas Soluciones en la Nube: como ya no depende de los servicios de la capa de integración de los sistemas legados, los equipos de desarrollo pueden enfocarse solo en sus aplicaciones, mejorando los tiempos de desarrollo de sus soluciones.
Sepa Más
Si te interesó el tema, sepa que es importante contar con el soporte de una compañía con experiencia en el desarrollo y operación de ese tipo de sistema de replicación, y TruStep puede apoyarte en ese camino.
Contata a nosotros. Ocupa el chat en la parte inferior derecha de nuestro sitio, o entonces el formulario de contacto. Te esperamos para comprender su escenario en una conversación, mostrarte más detalles acerca de cómo implementamos y operamos ese proyecto de replicación de datos en tiempo real a través de streaming de datos, y evaluar en conjunto como una solución semejante podría ayudar su negocio a mejorar la atención a sus clientes.