A necessidade
O projeto que desenvolvi numa grande cooperativa financeira chilena em 2021 e 2022 partiu de uma realidade comum a várias empresas: a era digital trouxe uma necessidade imperativa para implementar vários canais digitais de atendimento aos clientes. Muito antes disso, a empresa já possuía um bus de serviços para suas aplicações internas, e a solução natural foi reaproveitá-lo. Entretanto, ele não foi desenhado para a magnitude de escala que a proliferação desses canais e aplicações na nuvem trouxe.
O que se seguiu então foram vários ciclos de otimização e redimensionamento nessa camada de integração, até o ponto que o custo para mantê-la tornou inviável essa abordagem. Nos momentos extremos de carga, a camada de integração já não era mais capaz de suportar a demanda, colapsando e levando consigo a disponibilidade de todas as aplicações que dependiam dela, sejam internas ou na nuvem. E levar essa aplicação de core bancario para a nuvem estava fora de cogitação. O sistema havia sido implementado com tecnologia mainframe legada, de forma que a magnitude e os riscos envolvidos nesse tipo de empreitada tornava essa alternativa pouco atrativa.
A ideia de desacoplar os canais digitais e aplicações na nuvem dos sistemas core da empresa surgiu naturalmente: elas passariam a utilizar fontes de dados nativas na nuvem, aliviando a carga gerada sobre a camada de integração. E os dados seriam copiados desde os sistemas legados para essas novas fontes de dados utilizando as mesmas técnicas de ETL que os times de tecnologia já estavam acostumados a desenvolver, nos mesmos ciclos de processamento batch existentes.
Tudo certo do ponto de vista técnico, correto? Não exatamente: os clientes desses canais digitais demandam por informações rápidas na ponta do dedo, e não admitem esperar até o dia seguinte para que uma transação que foi efetuada agora seja refletida no seu celular, por exemplo. É justamente ao pensar sobre essa questão que a idéia de utilizar streaming de dados integrado com captura de transações em tempo real começou a fazer sentido!
Uma Solução Criativa e Robusta
A captura de transações em tempo real consiste em registrar, da forma menos invasiva possível, cada insert/update/delete que acontece na base de dados de origem. Dessa forma é possível replicar as informações em outra base de dados de destino executando a mesma sequência de operações originalmente registrada. Existem várias maneiras de fazer isso. Uma alternativa com custo/benefício adequado é a utilização de ferramentas que capturam os logs de transação nativos nos bancos de dados relacionais. Elas traduzem essa informação para um formato mais aberto, um json por exemplo, e envia os CDCs para algum destino desejado, no nosso caso um cluster de streaming de dados.
E por que streaming de dados? As ferramentas disponíveis atualmente trazem uma mescla interessante entre escalabilidade, custo e flexibilidade que nos permitem atender a todos os requisitos de um projeto desse tipo. Com ela, é possível atender a demanda altamente imprevisível e variável de throughput gerada a partir das transações do sistema core da empresa e, ao mesmo tempo, realizar as operações de ETL em tempo próximo ao real. Além disso, se o sistema for bem desenhado, a plataforma de streaming pode ser utilizada para todo tipo de análise de dados, desde sistemas de detecção de fraude até aprendizagem de máquina e inteligência artificial. No caso do nosso projeto, a plataforma de streaming escolhida foi Apache Kafka.
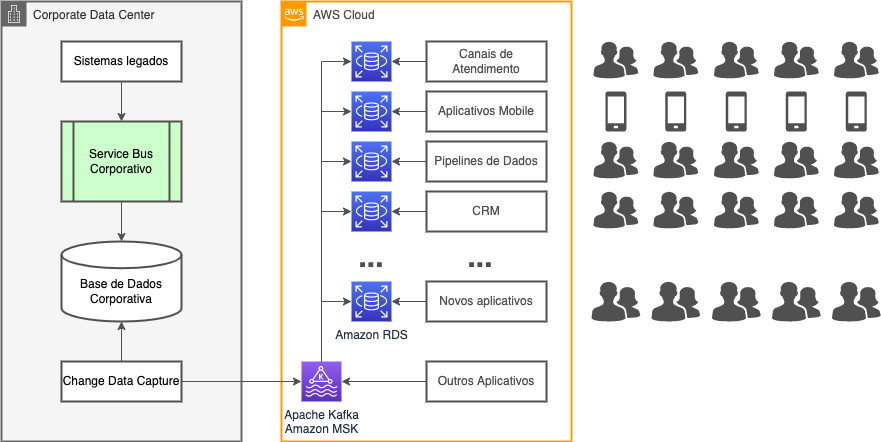
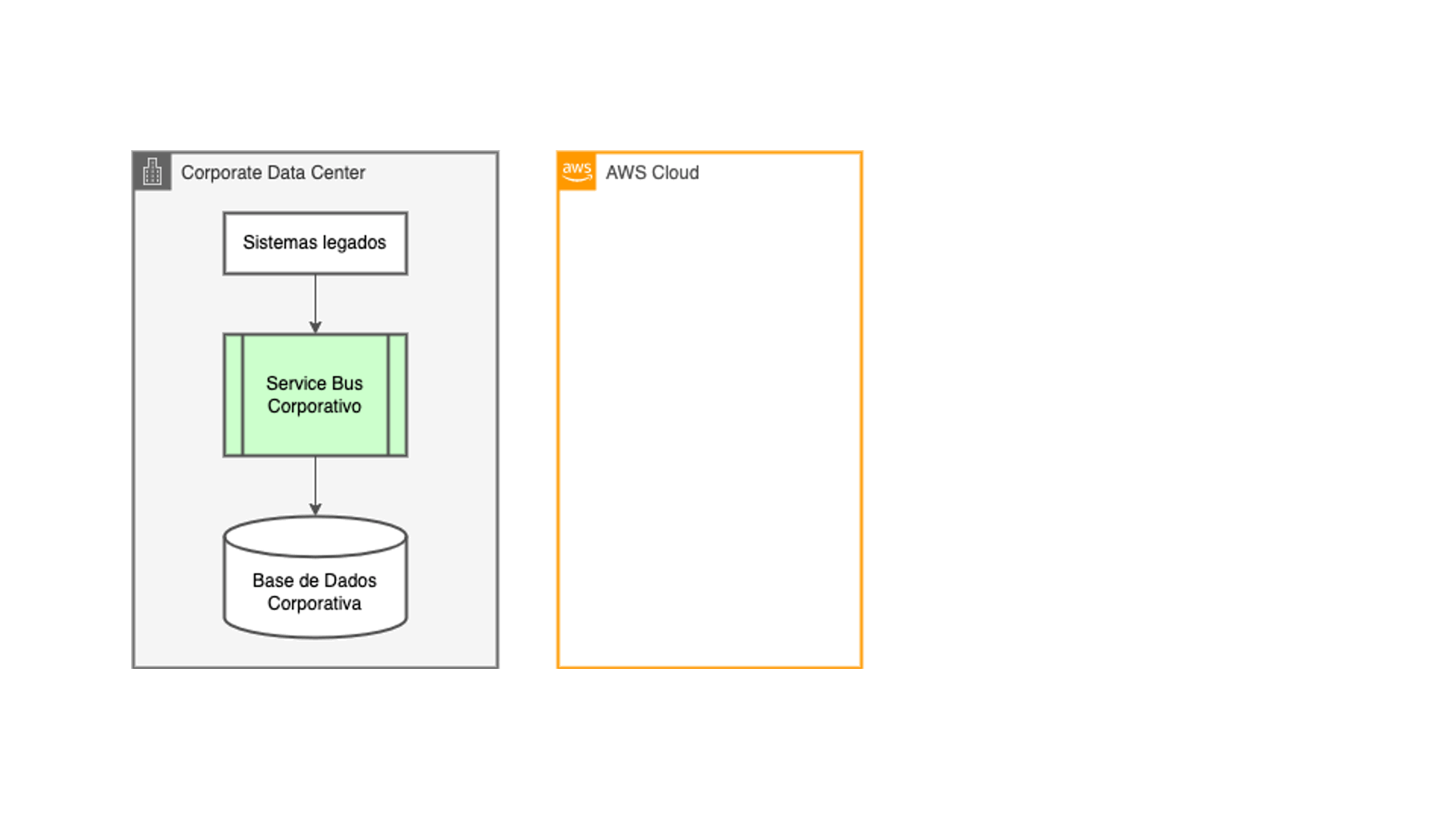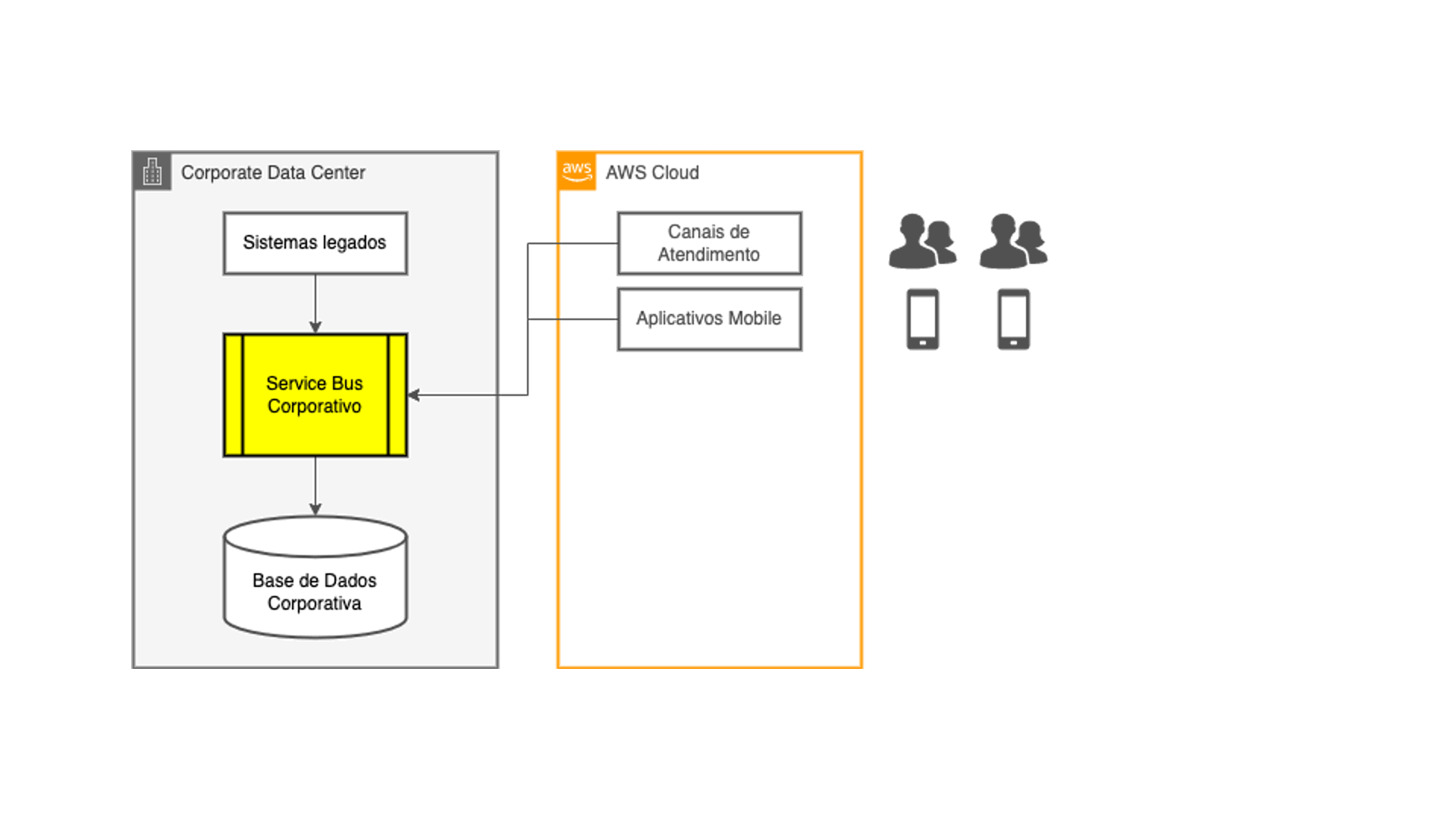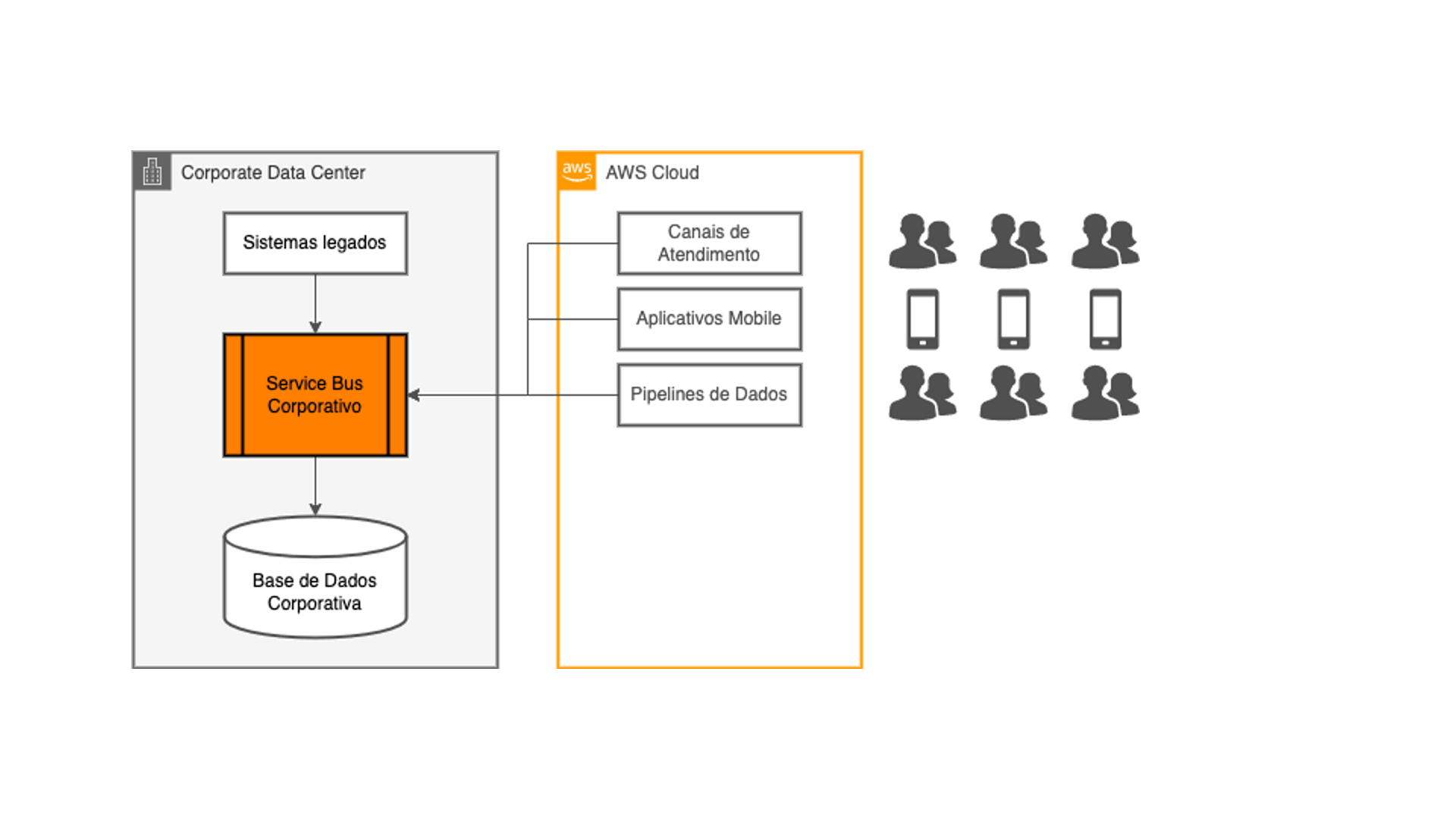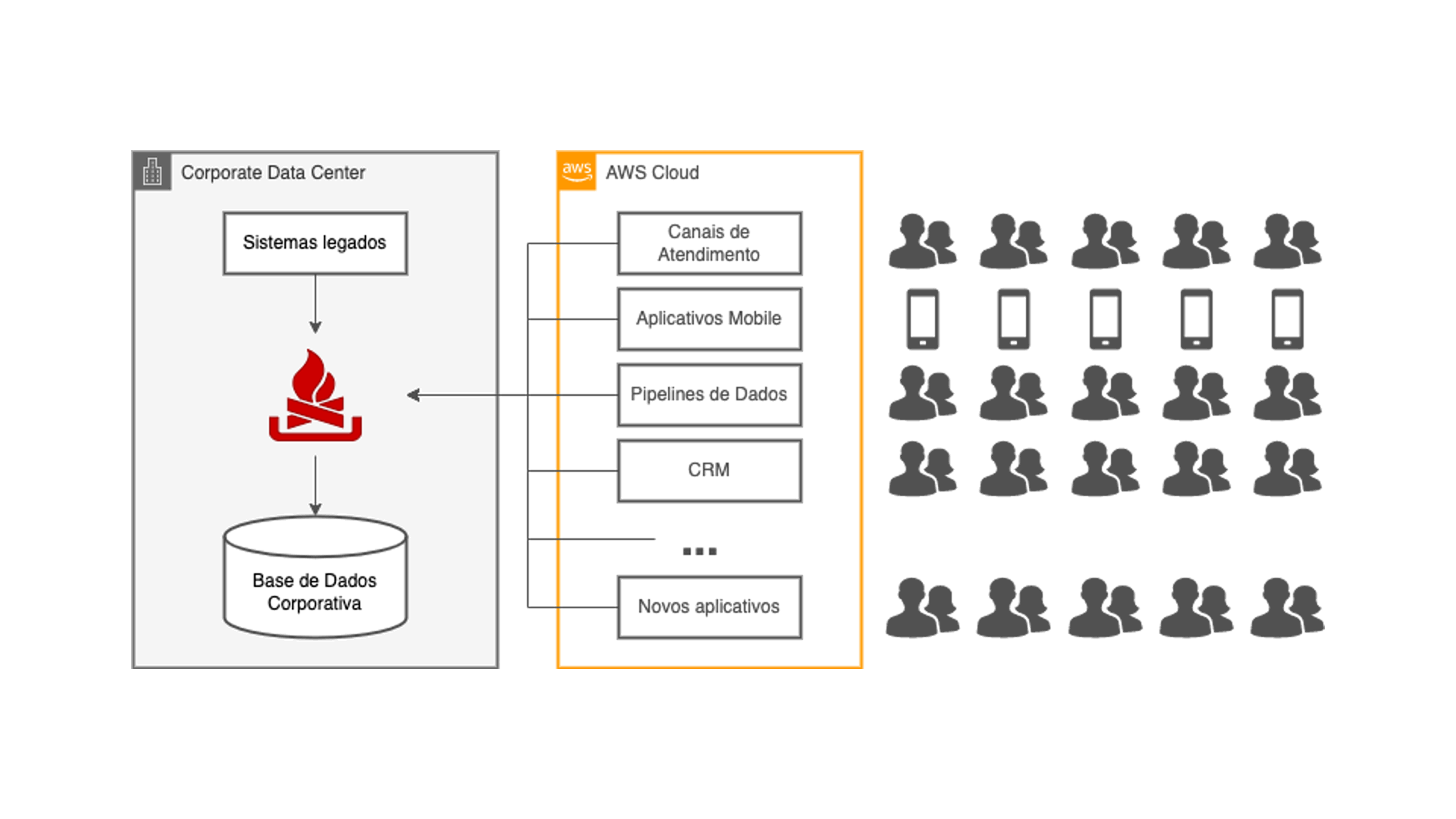
O diagrama mostra os principais componentes da solução de replicação de dados adotada no projeto. Nela vemos que o acesso aos dados do sistema core deixa de ocorrer através do bus de serviços. Ao invés disso, uma ferramenta conecta-se diretamente ao banco de dados, extraindo os CDCs e enviando-os para um serviço AWS MSK gerenciado pela AWS, que nada mais é que um cluster Apache Kafka.
Dentro da plataforma Kafka ocorrem todas as transformações ETL necessárias para compatibilizar os modelos de dados utilizando Kafka Streams. Dali então as informações são enviadas por conectores Kafka Connect para as bases de dados RDS criadas especificamente para cada uma das aplicações na nuvem. Tudo isso numa escala de tempo muito próxima do tempo real da transação original.
Os Desafios
E tudo são flores com essa nova arquitetura? Obviamente não. Existem vários desafios que surgem tanto na construção quanto na operação desse novo tipo de sistema. Alguns deles queremos destacar:
- Paradigma relacional versus orientação a eventos: o primeiro desafio que surgiu foi com o time de desenvolvimento. Um sistema baseado em streaming de dados é essencialmente um sistema orientado a eventos. Apesar de existir uma equivalência natural entre um stream de dados e tabelas relacionais, compreender as diferenças e semelhanças entre ambos exigiu uma mudança de paradigma;
- Compatibilização e consistência de modelos de dados: no mundo legado muitas vezes os dados não se encontram normalizados. E mesmo se estiverem normalizados, a integridade dos dados pode não ser garantida na base de dados, como por exemplo a integridade referencial. Além disso, as aplicações modernas podem utilizar conceitos não relacionais, o que pode trazer um desafio adicional na hora de realizar as operações de transformação de dados;
- Conhecimento do modelo legado incompleto ou disperso: muitas vezes os sistemas legados possuem modelagem de dados que poucas pessoas conhecem, que se encontra disperso entre vários membros da equipe ou até mesmo que já não está mais na empresa. Por serem sistemas desenhados a muito tempo, com paradigmas de programação já não utilizados, o conhecimento e o tempo necessários para extrair as informações desses tipos de sistemas não pode ser subestimado;
- Tratamento de exceções e casos não previstos: definir como tratar os casos não previstos é tão importante quanto definir o mapeamento entre os dados entre a origem e o destino. Negligenciar aspectos relacionados ao tratamento de exceções pode gerar um grande problema na hora de colocar esse tipo de sistema em produção. Desenvolver sobre bases de dados representativas também é fundamental para detectar condições de contorno e inconsistência nos dados;
- Monitoramento e resposta a falhas: uma vez que os pipelines de dados entram em operação, o monitoramento e resposta a falhas deve ser constante, pois agora tudo acontece em tempo real e a resposta aos incidentes deve ocorrer prontamente. Por isso, todos os aspectos passíveis de automatização devem ser considerados, sempre pensando em diminuir o tempo de resposta na ocorrência de imprevistos. Todos os aspectos, desde a automatização de instalação de novas versões até a resposta frente a chegada de um dado inconsistente, passando pelo auto-escalamento e auto-recuperação de falhas de hardware e software, devem ser pensados e automatizados. Isso exige uma nova mentalidade e postura dos times de desenvolvimento, arquitetura e operações.
Esses são apenas alguns dos desafios que tivemos que enfrentar ao longo da implementação dessa solução. Entretanto, os benefícios oferecidos compensaram o trabalho necessário para vencê-los.
Os Benefícios
Como resultado, a carga gerada por essas aplicações agora é completamente tratada dentro do escopo da nuvem, e não sobrecarrega os aplicativos legados on-premise. Abaixo listamos alguns dos benefícios obtidos com a solução:
- Disponibilização de Dados em Tempo Real: os dados são disponibilizados para as aplicações na nuvem praticamente ao mesmo tempo que foram processados pelos sistemas de core bancário, brindando os clientes com mais agilidade nos canais digitais;
- Sistemas Legados mais Estáveis e Econômicos: o desacoplamento entre os aplicativos na nuvem e a camada de integração aumentou a estabilidade dessa camada, na medida que a pressão gerada pela demanda variável da nuvem é tratada com escalamento automático na própria nuvem, onde é mais fácil adequar-se à demanda e ao mesmo tempo controlar os custos;
- Novas Possibilidades de Exploração dos Dados do Negócio: a plataforma de streaming abriu novas possibilidades de exploração dos dados em tempo real através de técnicas de análise preditiva, aprendizagem de maquina e inteligência artificial;
- Mais Agilidade no Desenvolvimento de Novas Soluções na Nuvem: ao não depender mais dos serviços na camada de integração dos sistemas legados, os times de desenvolvimento podem focar apenas em sua aplicação, melhorando os tempos de desenvolvimento de suas soluções.
Saiba Mais
Se você se interessou pelo assunto, saiba que é importante contar com apoio de uma empresa com experiência em desenvolver e operar esse tipo de sistema de replicação, e a TruStep pode te apoiar nessa jornada.
Entre em contato conosco. Utilize o chat no canto inferior direito do site para entrar em contato, ou utilize nosso formulário de contato. Te esperamos para entender seu cenário numa conversa ao vivo, mostrar mais detalhes sobre como implementamos e operamos esse projeto de replicação de dados em tempo real através de streaming de dados, e avaliar em conjunto como uma solução similar poderia ajudar seu negócio a atender melhor seus clientes.